Christian Nölle ist Abteilungsleiter im ZIM an der Uni Wuppertal und verantwortlich für die Bereiche Anwendungen, E-Learning, Qualifizierung und Support.
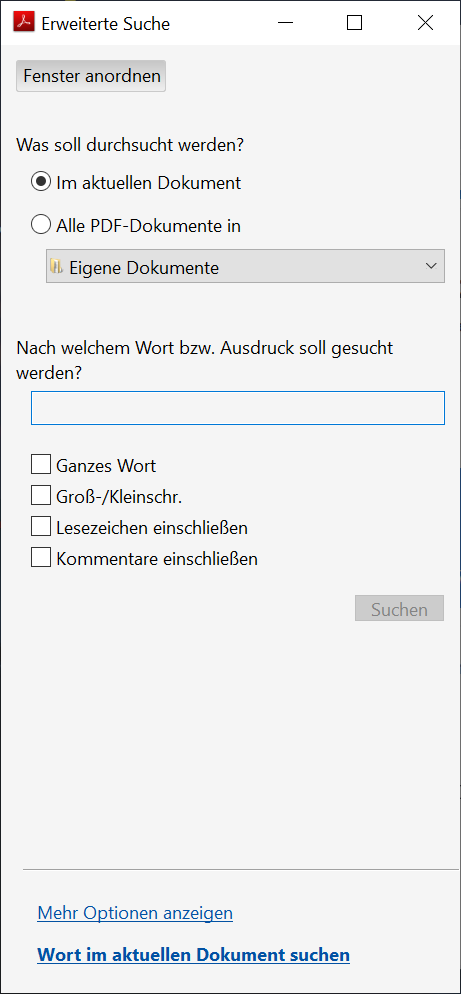
Da stand ich gerade vor dem Problem, dass ich eine relativ komplexe Beschaffung nach einem bestimmten Produkt und dessen Lieferanten durchsuchen wollte. Jetzt umfasst dieser Beschaffungsantrag aber nicht einen Auftrag, sondern rund 18 Einzelaufträge an die verschiedensten Firmen. Versuche mit der Windows Suche schlugen fehl, diese indexiert wohl keine PDF inhaltlich – oder zumindest bei mir tut sie das nicht. Aber siehe da, der Acrobat Reader kann das:
Mit der Tastenkombination [Strg] + [Shift] + [F] ruft man die Suchmaske auf
Auswahl von “Alle PDF-Dokuemnte in”
Ordner oder Pfad mit den PDFs auswählen
Suchwort eingeben und ggfs. Optionen entsprechend setzen.
Bisher hatten Nutzer*innen der Webkonferenzsoftware Zoom nur die Möglichkeit, den Zutritt zu Ihrer Konferenz, Veranstaltung oder Besprechung auf “angemeldete Nutzer*innen” zu beschränken. Dies ermöglicht aber nur eine geringe Kontrolle, welcher Personenkreis den nun tatsächlich da im Warteraum auftaucht. Ein Zoom-Konto ist schnell erstellt und das Scriptkiddie aus dem Kinderzimmer oder der Zoombomber aus einer Trollfabrik kann das auch.
Aus diesem Grund haben wir uns das Feature mal genauer angesehen und festgestellt, dass wir das sehr wohl auch auf unsere Organisation einschränken können.
Mein Kollege Joachim hat ja schon einen oder zwei erste Einblicke in die Arbeiten am Videoportal der Bergischen Universität gegeben. Ich würde mit euch nun gerne einen Blick unter die Motorhaube werfen und zeigen, dass das, was wir am Vergaser (IIS) nicht einstellen konnten, einfach durch einen ordentlichen Turbo (varnish) wieder wettgemacht haben. 😉 Nun aber genug der Autobilder, starten wir mal…
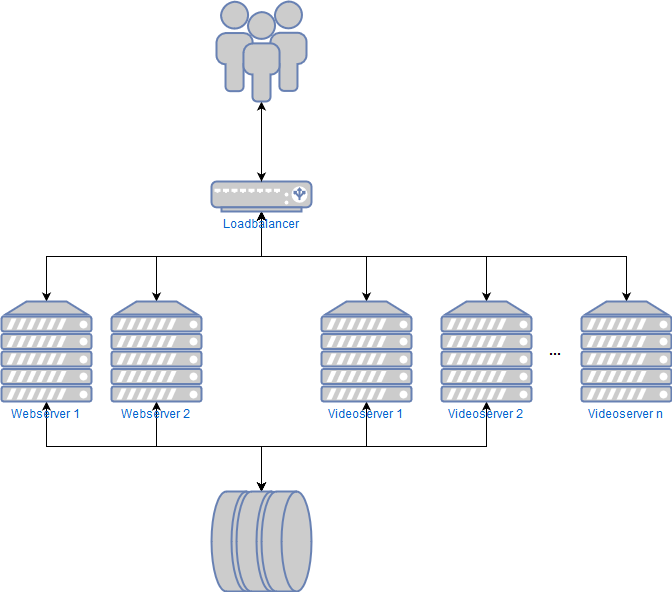
Der Aufbau des Videoportals der Uni Wuppertal ist nicht so ganz trivial, hier sind eine Menge Server im Spiel, welche miteinander interagieren und sich gegenseitig beeinflussen. Folgend daher nur die schematische Darstellung der für die Auslieferung wichtigen Server. Nur diese sind für uns relevant, schließlich ist ja hier der Flaschenhals zu erwarten.
Das Setup des Videoportals schematisch vereinfacht
Bei jedem Aufruf eines Videos werden die Elemente, die die Webseite des Videoportals ausmachen, von den beiden Webservern ausgeliefert. Die Fragmente der Videos, also das, worauf es ankommt, werden durch die Videoserver und einen Loadbalancer an die User geschickt. Aber eben leider nicht an besonders viele gleichzeitig, relativ schnell kam das System ins Stolpern, das hätte den Anforderungen von Uni@Home in der Form nicht standgehalten.
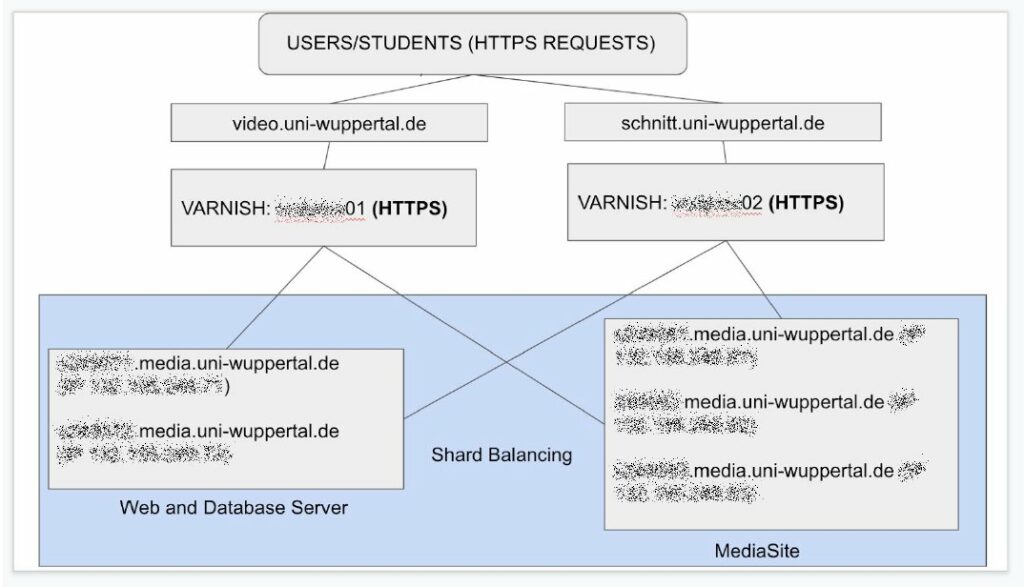
Da musste also mehr Power rein und das ganze sollte dann auch redundanter werden. Wir haben aus diesem Grund Kontakt mit der Firma varnish AB gesucht, da wir das Hauptprodukt, den varnish cache, schon für unsere TYPO3 Server verwenden und damit sehr zufrieden sind. varnish AB hat uns dann sehr zeitnah und absolut unbürokratisch nach Auftrag einen Techniker zur Seite gestellt. Lucas hat dann unser Setup umgebaut und vor unsere Video- und Webserver des Videoportals eine redundante varnish pro Installation realisiert.
Schematische Darstellung des varnish Video Streaming und VoD Setups
Die Architektur basiert auf einem 1-tier Aufbau mit zwei varnish Servern, die so konfiguriert sind sowohl die Web- als auch MediaSite Server zu erreichen. Das Setup ist in der Lage, die beiden Varnish Instanzen in einer aktiven/aktiven Konfiguration vorzuhalten. In normalen Situationen ist varnish01 für den Webseiteninhalt zuständig und varnish02 wird für das Streaming bzw. die Video on Demand Auslieferung verwendet. In Ausfallsituationen ist jede Instanz in der Lage mit den anderen Inhalten (Web und Video) umzugehen.
Die dahinterliegende Konfigurationsdatei in VCL (Varnish Configuration Language) für die beiden Server ist ziemlich schlank gehalten und konzentriert sich auf das Caching der Videofragmente. Die Webseite des Videoportals wird hierbei kaum zwischengespeichert, hier handelt es sich hauptsächlich um statische HTML und CSS Dateien, welche auch von einem IIS schnell ausgeliefert werden können. 😉 Die Videofragmente jedoch sind gut zu cachen und werden durch die beiden Server für drei Tage zwischengespeichert.
//#dont cache manifests
if (bereq.url ~ ".mpd|.m3u8|manifest") {
set beresp.uncacheable = true;
} else {
//#cache video fragments for max 3 days
set beresp.ttl = 3d;
}
Wichtig ist, die manifest Dateien nicht zu cachen, daher werden diese auf uncacheable gesetzt.
Weiterhin verlassen wir uns auf die “Probe”-Funktionalität von varnish. Damit können wir feststellen, ob die entsprechenden Mediasite-Server (Web und Video) denn überhaupt betriebsbereit sind oder ob varnish diese erstmal als “krank” markiert und nicht mehr darauf zugreift.
Für die Streamingserver lassen wir varnish ein sehr kleines .mp4 Video anfragen ;), die Webserver (siehe unten) werden auf die funktionierende API geprüft.
Interessant ist sicherlich auch noch die Skalierung der Maschinen, wir verwenden hier je Maschine einen RAM Cache in der Größe von ca. 112 GB, insgesamt verfügen die beiden Server jeweils über 128 GB Arbeitsspeicher. Varnish arbeitet hier mit dem brandneuen Memory Govenor in Verbindung mit der Massive Storage Engine.
Die o.a. Parameter im Startaufruf von varnish in Verbindung mit folgenden Zeilen in der mse.conf
env: {
id = "myenv";
memcache_size = "auto";
};
sorgen dafür, dass varnish im Rahmen des memory_targets seinen Bedarf selbstständig an die Begebenheiten anpassen kann.
Alles in allem ein einfaches wie bestechendes Setup, welches wir ohne die tatkräftige Hilfe der Mitarbeiter*innen bei varnish AB sicherlich nicht in der Kürze der Zeit so elegant realisiert bekommen hätten. Also Charlotte, Lucas und Jonatan: You rock! Danke!
Wir haben darüber bereits einen Meldung (ZIM Webseite | Hausmitteilung) veröffenlicht: Seit April 2019 gibt es keine freien, öffentlichen Updates für Java SE 8, JDK 8 und JRE 8 von Oracle. Wer diese Versionen weiterhin zwingend einsetzen möchte, muss eine ‘Subscription’ mit Oracle abschließen.
Wen trifft das an der Bergischen Universität Wuppertal?
Alle Rechner, die nicht ausschließlich für Lehrzwecke (also eigentlich alle außer Poolrechner) verwendet werden.
Alle Rechner/Clients/Server (=Maschinen), die Oracle Java SE/JRE/JDK 8 verwenden und dessen Nutzung nicht eindeutig vom Lizenzvertrag des Dritthersteller* abdeckt ist.
Alle Installationen der Updates 8u211, 8u212 (ab Mitte April 2019) dürfen nur über ein kostenpflichtiges Abonnement/Subscription vorgenommen werden.
Welche Möglichkeiten gibt es?
Es kann eine Subscription abgeschlossen werden. Problem: Die Kosten sind enorm: Pro Client sind ca. 10-28 € pro Jahr fällig. Bei Servern erfolgt die Lizenzierung über die Cores -> Bei virtuellen Maschinen werden alle physischen Cores, auf denen die Maschine laufen kann, berechnet!
Man kann auf die jeweils kostenfreie neue Java Version migrieren. Die nächste Version wäre Java 11, dann Java 12, etc (s. Supportroadmap). Problem: Halbjährige Migrationen sind aus praktischen Gründen schwierig umzusetzen.
Umsteigen auf eine OpenJDK 8 Variante: OpenJDK, Corretto, Zulu, AdoptOpenJDK, etc. Problem: Nicht alle Systeme lassen sich problemlos auf eine OpenJDK Variante umstellen. Es kann sein, dass bestimmte Funktionen nicht mehr verwendbar sind oder andere Probleme erscheinen.
Java im aktuellen Zustand belassen und keine neuen Updates mehr installieren. Problem: Es entstehen erheblich Sicherheitslücken, wenn Java nicht aktualisiert wird.
* Woher weiß ich, ob die Software, welche Java benötigt, nicht zusätzlich lizenziert werden muss?
Dies können Sie aus den Lizenzinformationen, Nutzungsvereinbarungen oder Produktinformationen ablesen. Oftmals sind die expliziten Informationen nicht direkt auffindbar. Halten Sie in den Vereinbarungstexten Ausschau nach den Begriffen ‘Oracle’, ‘Java’, ‘Dritthersteller’ oder ‘Third Party’. Wenn Sie Fragen zu den Lizenzbedingungen Ihrer eingesetzten Software haben, dann können Sie sich an software@uni-wuppertal.de wenden. Am besten senden Sie dann auch gleich die Lizenzvereinbarungen mit, falls diese vorhanden sind.
Hilfreiche Artikel, die das Verständnis der Problematik verdeutlichen, finden Sie unter den folgenden Links:
Hier finden Sie die veröffentlichte Nachricht über das allgemeine Supportende. Sie finden auf der Webseite weiterführende Informationen wie die Supportroadmap: https://www.java.com/de/download/release_notice.jsp
Da landete letzte Woche ja die brandneue Publikationsrichtlinie der Bergischen Universität Wuppertal auf meinen Schreibtisch, in der ich den Hinweis auf das akademische Identitätsmanagement sehr interessant fand. Insbesondere da das E-Learning Team des ZIM kurz vorher die Möglichkeit geschaffen hat, seine ORCID im Moodle Profil zu hinterlegen und damit auch dort auf sein Portfolio verweisen zu können. Wem ORCID jetzt gar nix sagt, dem sei zum einen die Lektüre entsprechenden Information auf den Webseiten der Bibliothek nahegelegt, ich klaue aber auch einfach mal dreist einen Absatz von dort:
Die ORCID iD ist eine eindeutige Kennung für Wissenschaftlerinnen und Wissenschaftler. Diese Autorenidentifikation kann mit dem Digital Object Identifier (DOI) als numerischer Code für Publikationen verglichen werden. Das DOI-System ist ein ISO-Standard und im wissenschaftlichen Publikationsprozess weit verbreitet. ORCID ist offen, nicht kommerziell sowie plattformübergreifend und gewährleistet die eindeutige Zuordnung einer Person zu ihrer Forschungsleistung.
Ich bin immer wieder im Job mit der Aussage von wissenschaftlichen Mitarbeiterinnen und Mitarbeitern konfrontiert, die die Universität verlassen: “Ich brauche aber meine Mailadresse noch, alle meine wissenschaftlichen Publikationen laufen darunter, die habe ich überall angegeben!”
Tun Sie das nicht! Geben Sie nicht ihre Mailadresse an! Wieviele Mailadressen hatten Sie schon im Laufe Ihrer wissenschaftlichen Karriere oder auch davor?! Auf wieviele davon haben Sie heute noch Zugriff? Und wieviele lebenslange Mailadressen wollen Sie über Ihr digitales Leben ansammeln?
Die ORCID hilft! Zwar natürlich nicht rückwirkend bei bereits publizierten – und womöglich gedruckten – Veröffentlichungen, aber für die Zukunft. Verwenden Sie die Möglichkeit Ihre Publikationen persistent in Ihrem Portfolio aufzunehmen! Die Nutztung der ORCID bietet neben der eindeutigen ID noch viele weitere Vorteile wie automatisierten Publikationslisten oder ein digitales Curriculum Vitae. Die Bibliothek hat hier umfassenden Informationen für Sie: https://www.bib.uni-wuppertal.de/de/a-z-seiten/orcid.html
Was mich abschließend dazu bringt, hier mal kurz aufzuzeigen, wie man das denn in Moodle einträgt:
Nach dem Login oben rechts in der Ecke auf sein Avatar/Bild/Profil klicken und “Einstellungen” auswählen. In dem dann folgenden Screen wählen Sie im Block “Nutzerkonto” “Profil bearbeiten” aus und rollen dann ganz nach unten. Eventuell müssen Sie den Punkt “Weitere Profileinstellungen” einmal ausklappen und finden dann das Feld, in welches Sie Ihre ORCID eintragen können. Danach erscheint dann der Link zu Ihrem ORCID Profil in Ihrer Moodle Profilansicht.