Mit dem Start des neuen Jahres 2023 haben wir die betagte Suche über die Webseiten der Bergischen Universität Wuppertal ausgetauscht. Wir betreiben ab sofort keinen eigenen Suchserver mehr, sondern binden die Google-Suche über alle Domains, die *.uni-wuppertal.de enthalten, auf der Webseite ein.
Die Vorteile liegen ziemlich klar auf der Hand: Google hat unsere Webseiten sowieso im Index, die Qualität der Suchergebnisse ist gut, warum daher nicht auch für unsere Webseite die angepasste Version der Suche verwenden?
Der Datenschutz bleibt gewahrt
Wir binden daher die sogenannte Programmable Search Engine (früher Custom Search) von Google ein. Die Einbindung erfolgt werbefrei und die Suche ist erst nach Aktivierung durch die Besuchenden verfügbar. Nach dem Klick des Such-Icons (Lupe) im Hauptmenü der Webseite erhalten sie folgenden Hinweis:
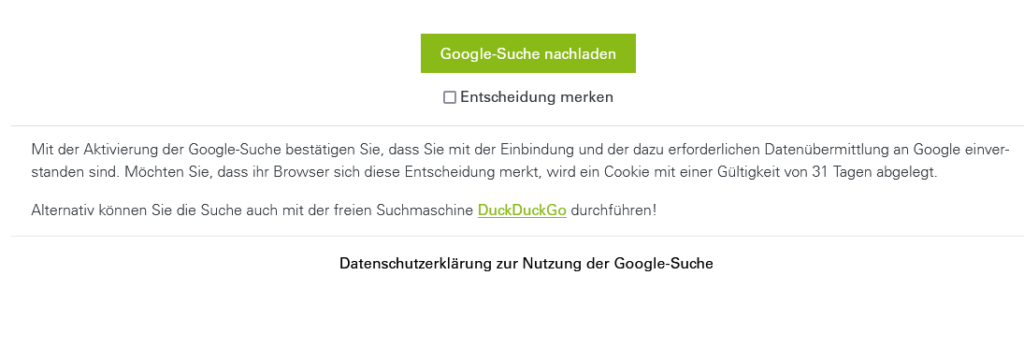
Diese Aktivierung sieht vor, die Google-Suche einmalig zu aktivieren, oder zu aktivieren und diese Entscheidung in einem Cookie für 31 Tage zu speichern. Wird die Entscheidung nicht gespeichert, muss beim nächsten Aufruf der Seite erneut eingewilligt werden.
Weitere Informationen zum Datenschutz der neuen Suche erhalten Sie auf der dafür bereitgestellten Webseite.
Suchbereich
Die Suchfunktion auf der zentralen Webseite der Universität unter www.uni-wuppertal.de durchsucht alle Subdomains, wie etwa zim.uni-wuppertal.de oder www.wiwi.uni-wuppertal.de.
Wird die Suche auf einer Seite wie zim.uni-wuppertal.de aktiviert, so werden nur Seiten in den Ergebnissen angezeigt, die ebenfalls unter zim.uni-wuppertal.de aufrufbar sind.
Wird die Suche auf einer TYPO3-Lehrstuhlseite aufgerufen, so ist der Suchbereich fakultätsspezifisch, so dass die Ergebnisse eingegrenzter und somit spezifischer sind. Eine Suche auf der Seite ees.uni-wuppertal.de liefert also nur Ergebnisse von Webseiten, die der Fakultät für Elektrotechnik, Informationstechnik und Medientechnik zugeordnet wurden.
Einbinden der Suche
Die Suche wird im Backend von TYPO3 eingebunden.
Der fakultätsspezifische Suchbereich ist dann direkt aktiviert. Bitte denken Sie auch an die englische Sprachversion Ihrer Seite, in der Sie ebenfalls die Suche aktivieren können – und die selbstverständlich nicht nur bereichs- sondern auch sprachspezifische Ergebnisse liefert.
Sollten Sie noch Webseiten vermissen, die nicht in TYPO3 gepflegt werden, aber Ihrer Fakultät zugeordnet werden sollen, so schreiben Sie an cms@uni-wuppertal.de.
Bitte haben Sie Verständnis, dass wir diesen Service nur für die beschriebenen Organisationseinheiten bereitstellen können. Leider können wir aufgrund des damit verbundenen Aufwands dies nicht für Einheiten unter der Ebene der Fakultät, wie bspw. einen Lehrstuhl oder ein Forschungsgebiet, realisieren.