Bei den Telefongeräten, die im Büro auf dem Schreibtisch stehen, wird zur Anruferkennung die Bezeichnung des Anschlusses innerhalb der Telefon-Anlage mitgegeben. “GREILING” z.B., wenn Sie von dem Fernsprech-Apparat mit der Durchwahl 2136 angerufen werden.
Sie können Anrufe aus der Telefon-Anlage der Uni auf eine beliebige Nummer weiterleiten. Die Information, wem der Anschluss, von dem aus angerufen wird, zugeordnet ist, wird allerdings nicht mitübergeben.
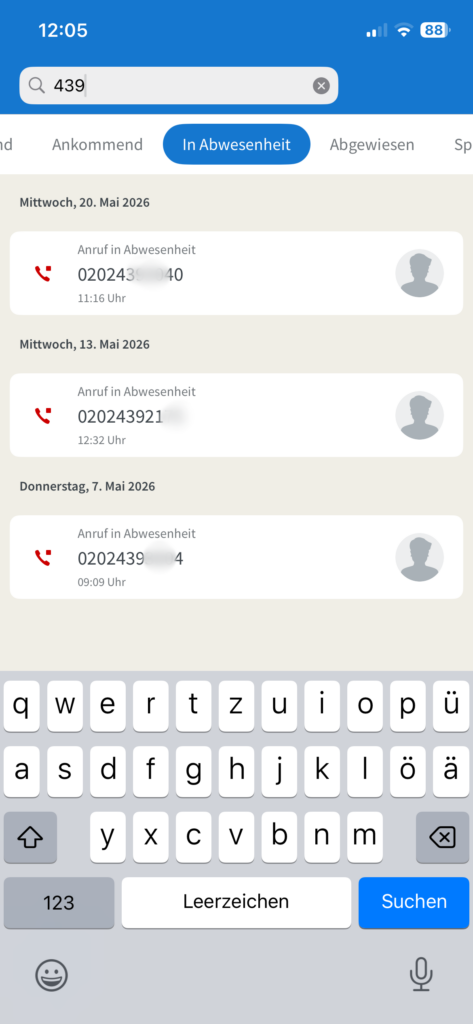
Es kann also sein, dass Sie in Abwesenheit versucht worden sind angerufen zu werden. Nur: wer war das?
Drei Anrufe in Abwesenheit – aber wer war das?
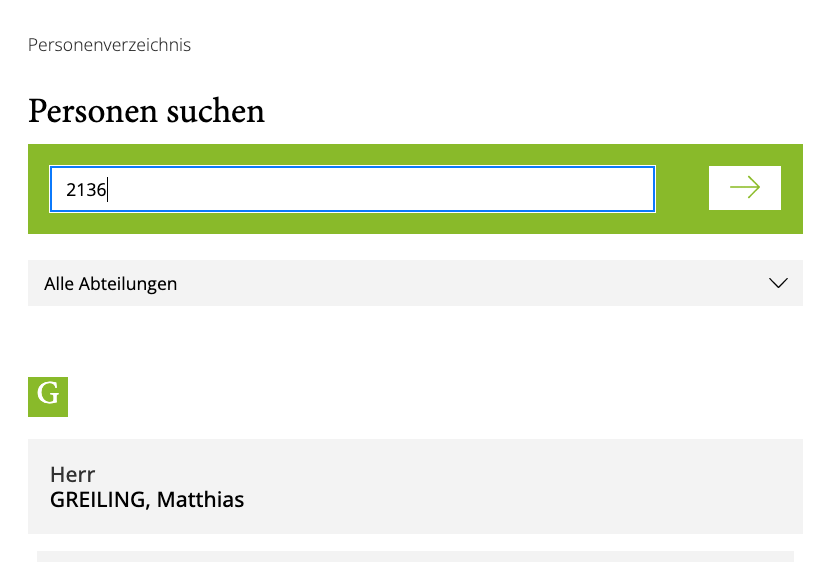
Wenn Sie sich im internen Netz der Bergischen Universität befinden, können Sie ab jetzt eine Rückwärtssuche in der normalen Telefonbuch-Suche auslösen.
Die Ziffernfolgen 4392136 oder 2136 führen zum gleichen Ergebnis
Telefonnummern, die nicht im Telefonverzeichnis des ZIM zu einer konkreten Person hinterlegt wurden, können leider nicht gefunden werden. Mehrfach eingetragene Nummern führen zu einer Liste aller diese Nummer beanspruchenden Personen.
Sie können jetzt der anrufenden Person selbst eine E-Mail schreiben oder mental vorbereitet ein Telefonat beginnen.
Mit dem Start des neuen Jahres 2023 haben wir die betagte Suche über die Webseiten der Bergischen Universität Wuppertal ausgetauscht. Wir betreiben ab sofort keinen eigenen Suchserver mehr, sondern binden die Google-Suche über alle Domains, die *.uni-wuppertal.de enthalten, auf der Webseite ein.
Die Vorteile liegen ziemlich klar auf der Hand: Google hat unsere Webseiten sowieso im Index, die Qualität der Suchergebnisse ist gut, warum daher nicht auch für unsere Webseite die angepasste Version der Suche verwenden?
Der Datenschutz bleibt gewahrt
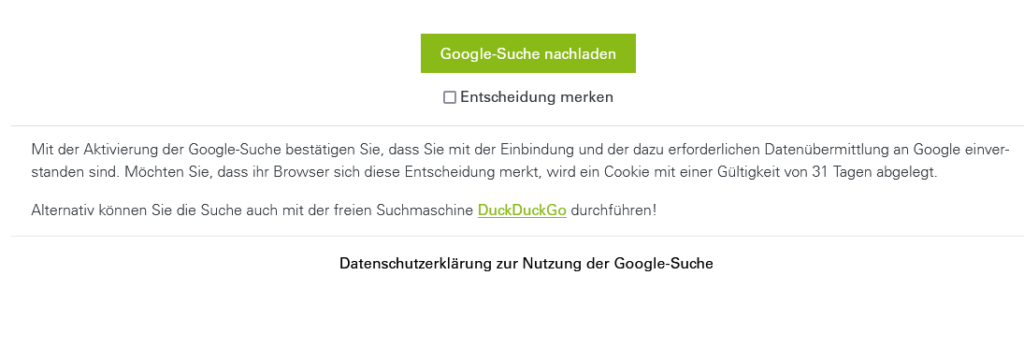
Wir binden daher die sogenannte Programmable Search Engine (früher Custom Search) von Google ein. Die Einbindung erfolgt werbefrei und die Suche ist erst nach Aktivierung durch die Besuchenden verfügbar. Nach dem Klick des Such-Icons (Lupe) im Hauptmenü der Webseite erhalten sie folgenden Hinweis:
Ansicht des Dialogs zur Suchaktivierung
Diese Aktivierung sieht vor, die Google-Suche einmalig zu aktivieren, oder zu aktivieren und diese Entscheidung in einem Cookie für 31 Tage zu speichern. Wird die Entscheidung nicht gespeichert, muss beim nächsten Aufruf der Seite erneut eingewilligt werden.
Wird die Suche auf einer Seite wie zim.uni-wuppertal.de aktiviert, so werden nur Seiten in den Ergebnissen angezeigt, die ebenfalls unter zim.uni-wuppertal.de aufrufbar sind.
Wird die Suche auf einer TYPO3-Lehrstuhlseite aufgerufen, so ist der Suchbereich fakultätsspezifisch, so dass die Ergebnisse eingegrenzter und somit spezifischer sind. Eine Suche auf der Seite ees.uni-wuppertal.de liefert also nur Ergebnisse von Webseiten, die der Fakultät für Elektrotechnik, Informationstechnik und Medientechnik zugeordnet wurden.
Der fakultätsspezifische Suchbereich ist dann direkt aktiviert. Bitte denken Sie auch an die englische Sprachversion Ihrer Seite, in der Sie ebenfalls die Suche aktivieren können – und die selbstverständlich nicht nur bereichs- sondern auch sprachspezifische Ergebnisse liefert.
Sollten Sie noch Webseiten vermissen, die nicht in TYPO3 gepflegt werden, aber Ihrer Fakultät zugeordnet werden sollen, so schreiben Sie an cms@uni-wuppertal.de.
Bitte haben Sie Verständnis, dass wir diesen Service nur für die beschriebenen Organisationseinheiten bereitstellen können. Leider können wir aufgrund des damit verbundenen Aufwands dies nicht für Einheiten unter der Ebene der Fakultät, wie bspw. einen Lehrstuhl oder ein Forschungsgebiet, realisieren.
Mein Kollege Joachim hat ja schon einen oder zwei erste Einblicke in die Arbeiten am Videoportal der Bergischen Universität gegeben. Ich würde mit euch nun gerne einen Blick unter die Motorhaube werfen und zeigen, dass das, was wir am Vergaser (IIS) nicht einstellen konnten, einfach durch einen ordentlichen Turbo (varnish) wieder wettgemacht haben. 😉 Nun aber genug der Autobilder, starten wir mal…
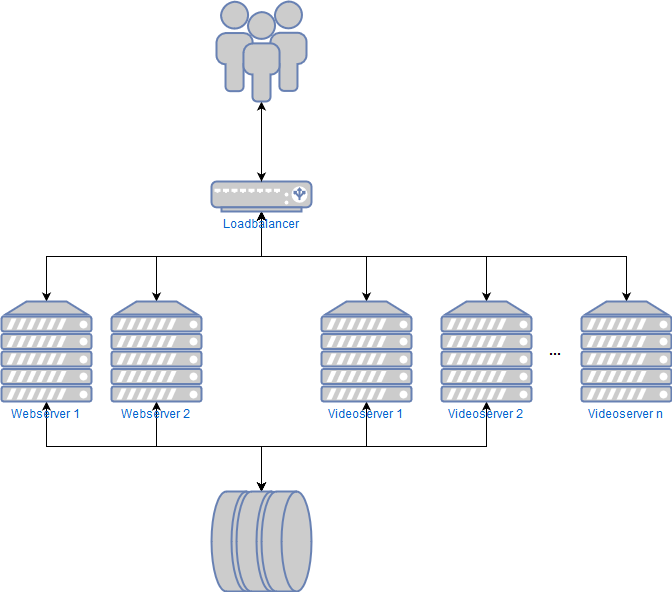
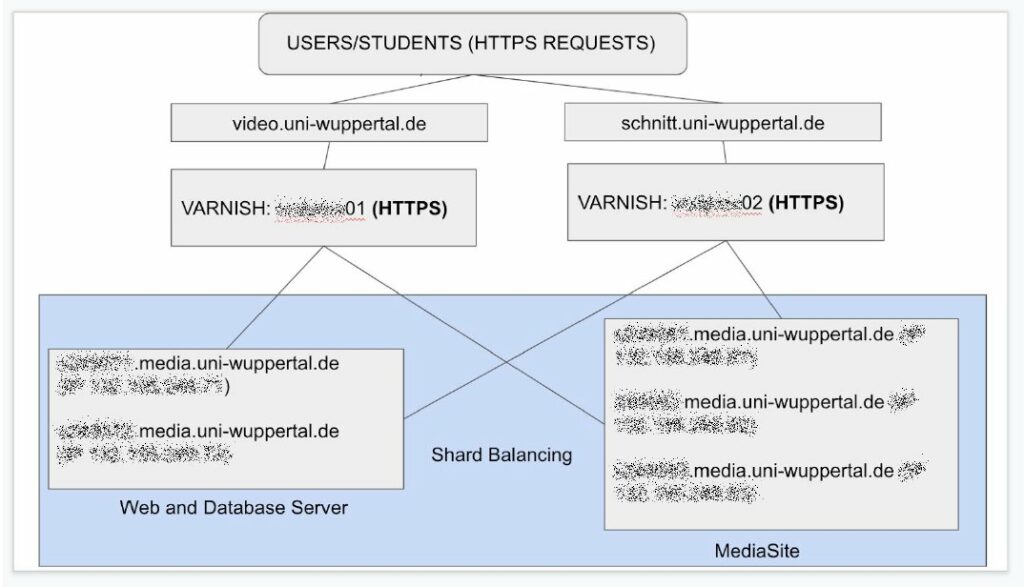
Der Aufbau des Videoportals der Uni Wuppertal ist nicht so ganz trivial, hier sind eine Menge Server im Spiel, welche miteinander interagieren und sich gegenseitig beeinflussen. Folgend daher nur die schematische Darstellung der für die Auslieferung wichtigen Server. Nur diese sind für uns relevant, schließlich ist ja hier der Flaschenhals zu erwarten.
Das Setup des Videoportals schematisch vereinfacht
Bei jedem Aufruf eines Videos werden die Elemente, die die Webseite des Videoportals ausmachen, von den beiden Webservern ausgeliefert. Die Fragmente der Videos, also das, worauf es ankommt, werden durch die Videoserver und einen Loadbalancer an die User geschickt. Aber eben leider nicht an besonders viele gleichzeitig, relativ schnell kam das System ins Stolpern, das hätte den Anforderungen von Uni@Home in der Form nicht standgehalten.
Da musste also mehr Power rein und das ganze sollte dann auch redundanter werden. Wir haben aus diesem Grund Kontakt mit der Firma varnish AB gesucht, da wir das Hauptprodukt, den varnish cache, schon für unsere TYPO3 Server verwenden und damit sehr zufrieden sind. varnish AB hat uns dann sehr zeitnah und absolut unbürokratisch nach Auftrag einen Techniker zur Seite gestellt. Lucas hat dann unser Setup umgebaut und vor unsere Video- und Webserver des Videoportals eine redundante varnish pro Installation realisiert.
Schematische Darstellung des varnish Video Streaming und VoD Setups
Die Architektur basiert auf einem 1-tier Aufbau mit zwei varnish Servern, die so konfiguriert sind sowohl die Web- als auch MediaSite Server zu erreichen. Das Setup ist in der Lage, die beiden Varnish Instanzen in einer aktiven/aktiven Konfiguration vorzuhalten. In normalen Situationen ist varnish01 für den Webseiteninhalt zuständig und varnish02 wird für das Streaming bzw. die Video on Demand Auslieferung verwendet. In Ausfallsituationen ist jede Instanz in der Lage mit den anderen Inhalten (Web und Video) umzugehen.
Die dahinterliegende Konfigurationsdatei in VCL (Varnish Configuration Language) für die beiden Server ist ziemlich schlank gehalten und konzentriert sich auf das Caching der Videofragmente. Die Webseite des Videoportals wird hierbei kaum zwischengespeichert, hier handelt es sich hauptsächlich um statische HTML und CSS Dateien, welche auch von einem IIS schnell ausgeliefert werden können. 😉 Die Videofragmente jedoch sind gut zu cachen und werden durch die beiden Server für drei Tage zwischengespeichert.
//#dont cache manifests
if (bereq.url ~ ".mpd|.m3u8|manifest") {
set beresp.uncacheable = true;
} else {
//#cache video fragments for max 3 days
set beresp.ttl = 3d;
}
Wichtig ist, die manifest Dateien nicht zu cachen, daher werden diese auf uncacheable gesetzt.
Weiterhin verlassen wir uns auf die “Probe”-Funktionalität von varnish. Damit können wir feststellen, ob die entsprechenden Mediasite-Server (Web und Video) denn überhaupt betriebsbereit sind oder ob varnish diese erstmal als “krank” markiert und nicht mehr darauf zugreift.
Für die Streamingserver lassen wir varnish ein sehr kleines .mp4 Video anfragen ;), die Webserver (siehe unten) werden auf die funktionierende API geprüft.
Interessant ist sicherlich auch noch die Skalierung der Maschinen, wir verwenden hier je Maschine einen RAM Cache in der Größe von ca. 112 GB, insgesamt verfügen die beiden Server jeweils über 128 GB Arbeitsspeicher. Varnish arbeitet hier mit dem brandneuen Memory Govenor in Verbindung mit der Massive Storage Engine.
Die o.a. Parameter im Startaufruf von varnish in Verbindung mit folgenden Zeilen in der mse.conf
env: {
id = "myenv";
memcache_size = "auto";
};
sorgen dafür, dass varnish im Rahmen des memory_targets seinen Bedarf selbstständig an die Begebenheiten anpassen kann.
Alles in allem ein einfaches wie bestechendes Setup, welches wir ohne die tatkräftige Hilfe der Mitarbeiter*innen bei varnish AB sicherlich nicht in der Kürze der Zeit so elegant realisiert bekommen hätten. Also Charlotte, Lucas und Jonatan: You rock! Danke!
Ein Einblick tief in den Maschinenraum unserer Webserver – Obacht es wird technisch:
Bis heute wurden fast alle Webseiten der Bergischen Universität über das nicht verschlüsselte Protokoll HTTP ausgeliefert. Nur bei Seiten, welche sensible Daten erheben und von denen wir darüber hinaus Kenntnis hatten, wurden verschlüsselt per HTTPS an die Anwender gebracht. Das ist nun anders – alle Webseiten, welche durch das zentrale CMS TYPO3 ausgeliefert werden und auf eine Domain mit der Endung .uni-wuppertal.de hören, werden standardmäßig verschlüsselt. Siehe hierzu unsere Meldung von Heute.
Damit das funktioniert, haben wir eine neue Software im Einsatz, welche die notwendigen Zertifikate verwaltet und gleichzeitig unseren Webbeschleuniger varnish beliefert: Hitch!
Nicht der Date-Doktor, sondern eher der TLS Doktor. Hitch ist ein sogenannter terminierender SSL-Proxy. Das bedeutet, er nimmt SSL-Verbindungen entgegen, entschlüsselt diese, reicht das ganze weiter an unseren Webproxy varnish, wartet auf Antwort, verschlüsselt diese wieder und liefert die Webseite an den Kunden aus. Hitch ist ein sogenannter “dummer” Proxy, kann also im Gegensatz zu HAProxy keinerlei Manipulationen vornehmen oder gar regelbasiert Unterscheidungen treffen, sondern nur “auspacken-weiterleiten-einpacken-ausliefern” betreiben 😉
Nachfolgend unsere Config dazu, da ist nahezu Standard und nix besonderes:
frontend = {
host = "*"
port = "443"
}
backend = "[127.0.0.1]:6086" # 6086 is the default Varnish PROXY port.
workers = 2 # number of CPU cores
daemon = on
user = "nobody"
group = "nogroup"
syslog-facility = "daemon"
# Enable to let clients negotiate HTTP/2 with ALPN. (default off)
#alpn-protos = "http/2, http/1.1"
# run Varnish as backend over PROXY; varnishd -a :80 -a localhost:6086,PROXY ..
write-proxy-v2 = on # Write PROXY header
# List of PEM files, each with key, certificates and dhparams
pem-file = "/path/to/pemfile.pem"
# Which ciphers do we support:
ciphers = "EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH"
Hitch lauscht auf 443, leitet intern alles an varnish auf Port 6086 weiter. Dazu verwendet er das PROXY V2 Protokoll. Damit nun alle Seiten der Universität aus TYPO3 verschlüsselt werden, weisen wir varnish an, alle auf Port 80 einkommenden Verbindungen für die Domains, welche auf uni-wuppertal.de enden, auf HTTPS, also Port 443, weiterzuleiten:
import std;
sub vcl_recv {
if (std.port(local.ip) == 80 && req.http.host ~ "(?i)uni-wuppertal.de$" ) {
if (req.http.host !~ "^(www.)?(ausnahmen|kommen|hierhin).uni-wuppertal.de$" ) {
set req.http.x-redir = "https://" + req.http.host + req.url;
return(synth(301));
}
}
}
Hier gibt es allerdings im zweiten if-Statement einen Ausnahmeblock, da wir für einige Domains im Namensraum uni-wuppertal.de derzeit keine Umleitung vornehmen. Diese lassen sich aber an zwei Händen abzählen.
Die eigentliche Umleitung wird dann in sub vcl_synth vorgenommen:
sub vcl_synth {
if (resp.status == 301) {
set resp.http.Location = req.http.x-redir;
return (deliver);
}
}
Wer also einen leistungsfähigen SSL Proxy benötigt, dem sei der leichtgewichtige Hitch durchaus an’s Herz gelegt. Das er aus dem selben Hause wie varnish kommt, ist für uns natürlich noch ein weiterer Vorteil.
Bisweilen stolpert man ja auf Plakaten in der Uni, im Netz oder in den Hausmitteilungen über den Adressen wie http://uni-w.de/bf, welche in einer Art Kurzform auf eine Seite der Universität Wuppertal oder einer ihrer Fakultäten, Einrichtungen oder Angebote verweist.
Nun stellt sich direkt die Frage: Wie komme ich denn an eine solche Adresse? Kann ich auch für meine Adresse eine solche Kurz-Version bekommen? Die Antwort ist denkbar einfach: Natürlich!
Das ZIM bietet den Service seit ca. April 2016 an und er ist über unsere Webseite (nur aus dem Uni-Netz) zugänglich. Einfach Adresse eingeben, auf “kürzen” klicken und schon wird die Kurz-Version angezeigt. Diese kann nun einfach kopiert und verwendet werden. Die Kurz-Version ist permanent, der Link läuft also nicht ab und kann direkt verwendet werden. Eine kleine Einschränkung gibt es allerdings: Wir kürzen nur Adressen aus dem Namensraum der Universität. Das bedeutet, nur Adressen, welche auf ein Ziel innerhalb der Uni verweisen, werden verarbeitet.
Ein Wort zum Datenschutz:
Externe Serviceanbieter, wie goo.gl, bit.ly etc., verwenden natürlich auch gerne die Daten, die mit einer solchen Kürz- und Klick-Dienstleistung verursacht werden, weiter. Das passiert bei unserem Service selbstverständlich nicht, alle Daten bleiben im Haus, sind auf unseren Server gespeichert und werden anonymisiert.
Welche Daten sind das?
Das sind die Ziel-Adresse, die Kurz-Version, Datum der Erstellung, anonymisierte IP des Erstellers (Hostanteil wird sofort entfernt) und die Anzahl der Klicks auf die Kurz-URL.