Nicht unbedingt täglich, aber doch allsemestrig füllen sich die E-Prüfungsräume am Campus Grifflenberg mit der sich nähernden vorlesungsfreien Zeit mit immer mehr Leben. Vor rund zwei Wochen ist die Hauptprüfungsphase des Sommersemesters gestartet und für uns als E-Prüfungsteam beginnt damit die arbeitsreichste Zeit des Semesters.
Bevor die ersten Prüflinge Platz nehmen konnten, gab es hinter den Kulissen jedoch noch einiges zu tun. In den vergangenen Wochen wurde unter anderem unser Pop-Up E-Prüfungsraum T.09.01 (48 Prüfungsplätze) wieder für die anstehende Prüfungsphase umgebaut. Tische und Netzwerktechnik wurden aus dem Lager befreit, Clients angeschlossen, Monitore, Tastaturen und Mäuse installiert sowie der Sichtschutz – gegen Stielaugen 🙂 – platziert.
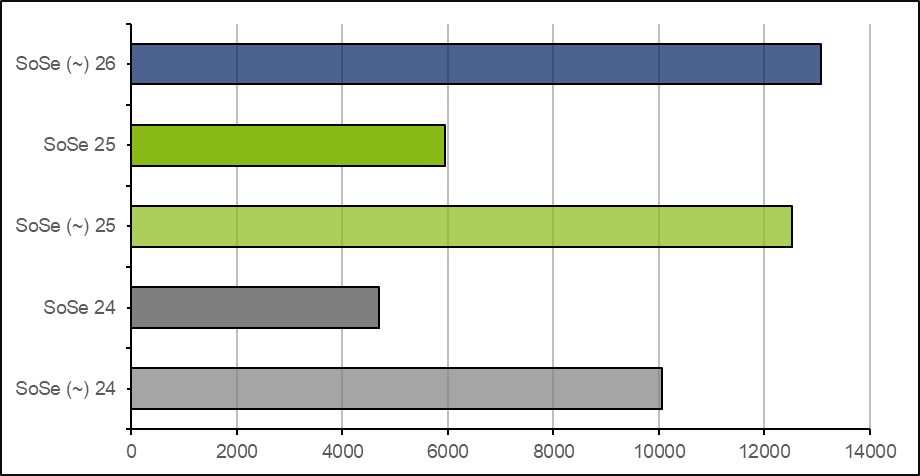
Gemeinsam mit dem ganzjährig für E-Prüfungen verfügbaren Raum L.11.22/27 (75 Prüfungsplätze) und dem Schulungsraum T.09.20/23 (30 Prüfungsplätze) stehen so bis zu 153 Prüfungsplätze gleichzeitig zur Verfügung. Was auf den Bildern nach einer schnellen Nummer aussieht, gestaltet sich im Sommer als schweißtreibende und zeitintensive Angelegenheit – ein Umstand, der im Nachgang mit zuckerhaltigen Kaltgetränken und dem ein oder anderen Wassereis aufgefangen wurde.
Bis zum Ende der vorlesungsfreien Zeit Mitte Oktober rechnen wir derzeit mit rund 13.000 Prüflingen, die sich auf etwa 150 Prüfungen verteilen. Dies verspricht einen erneuten Anstieg der Zahlen bezogen auf die letzten Sommersemester. Kaum verwunderlich … E-Prüfungen sind einfach klasse – praxisorientiert, nachhaltig und korrekturarm! Wer einmal zu uns stößt, der bleibt dabei 🙂
Abbildung: Vergleich von der bei Buchung der Räumlichkeiten durch die Prüfer*innen geschätzten (~) und dann tatsächlichen Teilnehmerzahlen der E-Prüfungen
Auch auf unserer Homepage gibt es passend zum Start der Prüfungsphase etwas Neues zu entdecken: Wer zu den Namen in den Mails schon immer mal ein Gesicht oder zu den Gesichtern in den Prüfungsräumen einen Namen haben wollte, der wird ab sofort auf unserer Team-Seite fündig:
Und wenn man schon einmal auf der Seite stöbert, dann entdeckt man noch so viel mehr! Wer sich mit dem Gedanken auseinandersetzt eine zukünftige Veranstaltung in Form einer E-Prüfung abzurunden, findet hier zahlreiche weiterführende Informationen sowie Tipps & Tricks:
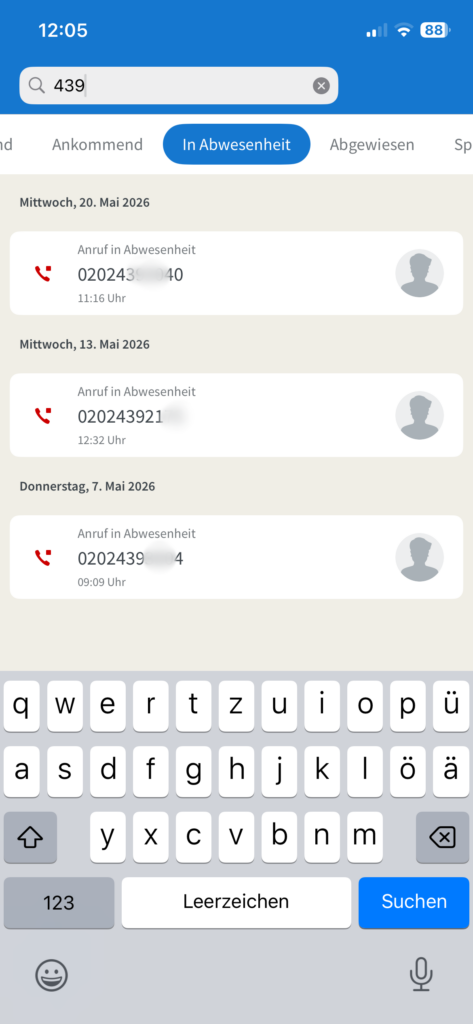
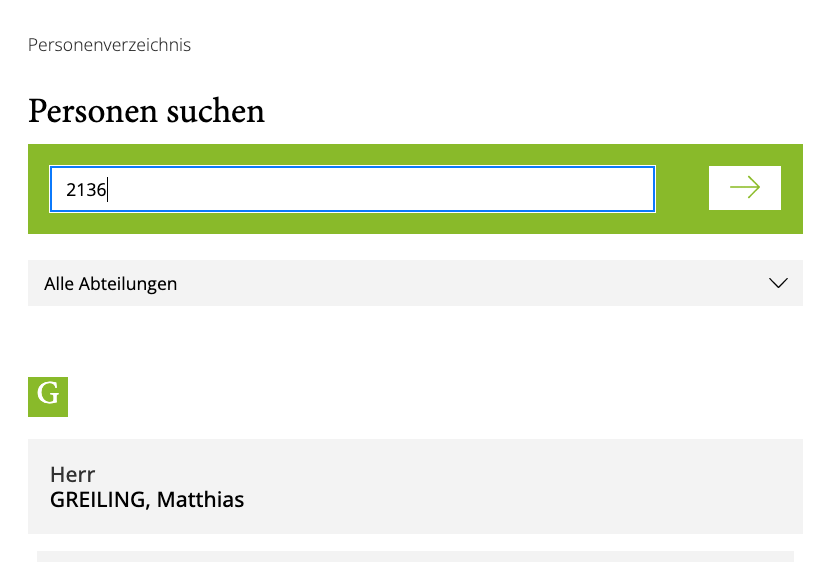
Bei den Telefongeräten, die im Büro auf dem Schreibtisch stehen, wird zur Anruferkennung die Bezeichnung des Anschlusses innerhalb der Telefon-Anlage mitgegeben. “GREILING” z.B., wenn Sie von dem Fernsprech-Apparat mit der Durchwahl 2136 angerufen werden.
Sie können Anrufe aus der Telefon-Anlage der Uni auf eine beliebige Nummer weiterleiten. Die Information, wem der Anschluss, von dem aus angerufen wird, zugeordnet ist, wird allerdings nicht mitübergeben.
Es kann also sein, dass Sie in Abwesenheit versucht worden sind angerufen zu werden. Nur: wer war das?
Drei Anrufe in Abwesenheit – aber wer war das?
Wenn Sie sich im internen Netz der Bergischen Universität befinden, können Sie ab jetzt eine Rückwärtssuche in der normalen Telefonbuch-Suche auslösen.
Die Ziffernfolgen 4392136 oder 2136 führen zum gleichen Ergebnis
Telefonnummern, die nicht im Telefonverzeichnis des ZIM zu einer konkreten Person hinterlegt wurden, können leider nicht gefunden werden. Mehrfach eingetragene Nummern führen zu einer Liste aller diese Nummer beanspruchenden Personen.
Sie können jetzt der anrufenden Person selbst eine E-Mail schreiben oder mental vorbereitet ein Telefonat beginnen.
Matrix ist ein Chat-System, mit dem man nicht nur innerhalb der Universität Wuppertal kommunizieren kann. Ähnlich wie bei E-Mail können auch Personen von anderen Matrix-Servern miteinander schreiben – sofern die beteiligten Server dafür freigeschaltet sind. Dieser Austausch zwischen Servern heißt Föderation.
Dieser Artikel erklärt, wie Mitarbeitende der Universität Wuppertal in Element/Matrix externe Personen in einen Raum auf dem eigenen Server einladen können – und was zu tun ist, wenn man selbst an einem Raum auf einem fremden Matrix-Server teilnehmen möchte.
Dort finden Sie weitere Hinweise zur Anmeldung, zur Nutzung von Element und zu aktuellen Regelungen oder Einschränkungen.
1. Begriffe kurz erklärt
Bevor es losgeht, helfen ein paar Grundbegriffe.
Matrix
Matrix ist das technische Protokoll hinter dem Chat-System. Es ermöglicht Nachrichten, Gruppenräume, Dateiübertragung und Kommunikation über Servergrenzen hinweg.
Element
Element ist ein Programm bzw. eine Weboberfläche, mit der man Matrix nutzen kann. Es ist vergleichbar mit einem E-Mail-Programm:
Matrix = die Technik
Element = die Anwendung, mit der Sie diese Technik bedienen.
Ein Matrix-Server ist der Server, über den die Kommunikation technisch läuft. Der technische Matrix-Server der Universität Wuppertal (Name: matrixsrv.uni-wuppertal.de) ermöglicht die Kommunikation.
Für die tägliche Nutzung ist aber vor allem die persönliche Matrix-ID wichtig.
Matrix-ID
Jede Person in Matrix hat eine eindeutige Adresse, die Matrix-ID.
An der Universität Wuppertal hat sie diese Form: @benutzername:uni-wuppertal.de
Beispiel: @mmustermann:uni-wuppertal.de
⚠️ Wichtig:
Die Matrix-ID ist nicht unbedingt identisch mit einer E-Mail-Adresse.
Sie beginnt mit @ und enthält nach dem Doppelpunkt den Matrix-Namensraum (hier: uni-wuppertal.de).
Externe Personen haben ebenfalls eine Matrix-ID, aber mit dem Servernamen ihrer eigenen Einrichtung oder ihres eigenen Matrix-Anbieters, zum Beispiel:
@maria.extern:matrix.org
@person:uni-andere-stadt.de
Raum
Was viele als „Kanal“, „Gruppe“ oder „Chat“ bezeichnen, heißt in Matrix meistens Raum.
Ein Raum kann zum Beispiel sein:
ein Projektchat,
ein Arbeitsgruppenraum,
ein Austauschraum mit externen Partnern,
ein Raum für Absprachen in einem Team.
Ein Raum kann zusätzlich eine Adresse haben, den sogenannten Raum-Alias. Dieser beginnt mit #, zum Beispiel: #projektgruppe:uni-wuppertal.de
Was ist ein Raum-Alias? Ein Raum-Alias ist eine lesbare Adresse für einen Raum (z. B. #projektgruppe:uni-wuppertal.de). Im Gegensatz zur Matrix-ID (die eine Person identifiziert) identifiziert der Alias einen Raum und kann zum einfachen Beitritt oder Teilen genutzt werden.
2. Was bedeutet „externe Person einladen“?
Eine externe Person ist in diesem Zusammenhang jemand, der kein Matrix-Konto der Universität Wuppertal nutzt, sondern ein Konto auf einem anderen Matrix-Server hat.
Beispiel für eine externe Matrix-ID: @maria.extern:matrix.org oder @maria.extern:uni-andere-stadt.de
Wenn die Matrix-Server miteinander kommunizieren dürfen (Föderation), kann diese Person trotzdem in einen Raum eingeladen werden, der auf dem Matrix-Server der Universität Wuppertal genutzt wird.
Was ist Föderation? Damit eine externe Person teilnehmen kann, müssen beide Matrix-Server die Föderation (den Austausch zwischen Servern) erlauben. Falls einer der Server die Föderation blockiert, kann die Einladung nicht zugestellt werden.
3. Voraussetzungen
Bevor Sie externe Personen einladen, sollten folgende Punkte geklärt sein:
Hinweise zur Anmeldung finden Sie in der offiziellen Dokumentation: 🔗 siehe Dokumentation
3.2 Ihre eigene Matrix-ID
Ihre Matrix-ID an der Universität Wuppertal hat diese Form: @benutzername:uni-wuppertal.de
Beispiel: @mmustermann:uni-wuppertal.de
Diese Kennung benötigen Sie insbesondere dann, wenn Sie selbst von einer externen Person in einen Raum auf einem anderen Matrix-Server eingeladen werden möchten.
3.3 Sie müssen Mitglied des Raums sein
Sie können nur Personen in Räume einladen, in denen Sie selbst Mitglied sind.
3.4 Sie benötigen die passenden Rechte im Raum
Nicht jedes Raummitglied darf automatisch weitere Personen einladen. Je nach Raum-Einstellung dürfen nur bestimmte Personen Einladungen aussprechen, zum Beispiel:
Moderatoren,
Administratoren des Raums.
Wenn Sie keine Einladung aussprechen können, wenden Sie sich an die Person, die den Raum erstellt oder verwaltet.
3.5 Die Matrix-ID der externen Person muss bekannt sein
Sie benötigen die vollständige Matrix-ID der externen Person.
Beispiel: @maria.extern:matrix.org oder @maria.extern:uni-andere-stadt.de
⚠️ Wichtig:
Nur der Anzeigename reicht nicht aus (kann mehrfach vorkommen).
Die Matrix-ID ist eindeutig.
3.6 Föderation muss möglich sein
Damit eine externe Person teilnehmen kann, müssen beide Matrix-Server die Föderation erlauben.
Wenn eine Einladung nicht funktioniert, kann es daran liegen, dass:
einer der beteiligten Server keine Föderation erlaubt,
bestimmte Server blockiert werden.
Details zu den aktuellen Möglichkeiten und Einschränkungen finden Sie in der Dokumentation: 🔗 siehe Dokumentation
4. Externe Person in einen Raum auf dem Uni-Wuppertal-Server einladen
Melden Sie sich mit Ihrem Uni-Zugang (ZIM-Account, den Sie zum Beispiel auch für Moodle nutzen) an. Die genaue Vorgehensweise ist in der Dokumentation beschrieben: 🔗 siehe Dokumentation
Warnung:
⚠️ Es wird dringend empfohlen, die Schlüsselsicherung zu nutzen, damit keine Nachrichten verloren gehen! Siehe dazu den Punkt 🔗 Sicherheit in der Dokumentation.
Schritt 2: Raum öffnen
Öffnen Sie den Raum, in den Sie die externe Person einladen möchten (z. B. Projektraum, Arbeitsgruppenraum).
Schritt 3: Mitgliederverwaltung öffnen
In Element finden Sie in einem Raum meist oben oder in der Seitenleiste einen Bereich für die Rauminformationen oder Mitglieder. Klicken Sie dort auf das Raum-Symbol (🏠) oder „Rauminfo“.
Hinweis: Die genaue Position und Bezeichnung kann je nach Element-Version oder App (Web, Desktop, Mobile) unterschiedlich sein.
Schritt 4: „Einladen“ auswählen
Klicken Sie auf die Funktion zum Einladen neuer Personen. Dort können Sie nach Personen suchen oder direkt eine Matrix-ID eingeben.
Schritt 5: Matrix-ID der externen Person eingeben
Geben Sie die vollständige Matrix-ID der externen Person ein.
Beispiel: @maria.extern:matrix.org oder @maria.extern:uni-andere-stadt.de
✅ Achten Sie darauf, dass:
die ID mit @ beginnt,
nach dem Doppelpunkt der Servername der externen Person steht (z. B. matrix.org oder uni-andere-stadt.de),
keine Leerzeichen enthalten sind,
keine E-Mail-Adresse statt der Matrix-ID eingetragen wird.
❌ Falsch: Eine E-Mail-Adresse wie maria.extern@example.org ist nicht automatisch eine Matrix-ID.
Schritt 6: Einladung senden
Wenn Element die externe Person findet oder die Matrix-ID akzeptiert, können Sie die Einladung absenden.
Die externe Person erhält dann auf ihrem eigenen Matrix-Server eine Einladung zu Ihrem Raum.
Schritt 7: Externe Person nimmt Einladung an
Die eingeladene Person muss die Einladung in ihrem eigenen Element-Client oder Matrix-Client annehmen. Erst danach ist sie Mitglied des Raums und kann Nachrichten lesen und schreiben – abhängig von den Einstellungen des Raums.
5. Wichtige Einstellungen im Raum
Bevor Sie externe Personen einladen, sollten Sie sich die Einstellungen des Raums ansehen.
5.1 Ist der Raum privat oder öffentlich?
Typ
Beschreibung
Privat
Nur für eingeladene Personen zugänglich.
Öffentlich
Kann je nach Einstellung gefunden und betreten werden, möglicherweise auch von Personen außerhalb der eigenen Organisation.
💡 Empfehlung: Für Arbeitsgruppen mit externen Partnern ist meistens ein privater Raum sinnvoll.
5.2 Wer darf Personen einladen?
In den Raumeinstellungen kann festgelegt sein, wer neue Mitglieder einladen darf.
Mögliche Varianten:
alle Mitglieder,
nur Moderatoren,
nur Administratoren.
💡 Empfehlung: Für vertrauliche Arbeitsräume empfiehlt es sich, Einladerechte bewusst zu vergeben.
5.3 Was können neue Mitglieder lesen?
Räume haben Einstellungen zur Nachrichtenhistorie.
Mögliche Varianten:
neue Mitglieder sehen nur Nachrichten ab dem Zeitpunkt des Beitritts,
neue Mitglieder können frühere Nachrichten sehen,
die Sichtbarkeit hängt von weiteren Raumeinstellungen ab.
⚠️ Wichtig: Wenn in einem Raum bereits vertrauliche Informationen stehen, sollte vor dem Einladen geprüft werden, ob neue Mitglieder alte Nachrichten sehen können.
5.4 Ist der Raum verschlüsselt?
Matrix-Räume können Ende-zu-Ende-verschlüsselt sein.
Vorteile: Nachrichten werden so verschlüsselt, dass sie nur von den beteiligten Geräten gelesen werden können.
Nachteile: Bei externen Teilnehmenden und neuen Geräten können gelegentlich zusätzliche Hinweise oder Bestätigungen erforderlich sein.
⚠️ Wichtig:
Wenn ein Raum verschlüsselt ist, sollten alle Beteiligten darauf achten:
ihre Geräte korrekt einzurichten,
Sicherungen bzw. Wiederherstellungsschlüssel nicht zu verlieren.
Nicht alle Matrix-Server aktivieren die Verschlüsselung standardmäßig. Prüfen Sie vor dem Beitritt zu einem externen Raum, ob dieser verschlüsselt ist – besonders bei vertraulichen Inhalten.
Weitere Hinweise zur sicheren Nutzung finden Sie in der Dokumentation: 🔗 siehe Dokumentation
6. Typische Probleme beim Einladen externer Personen
Problem
Mögliche Lösung
Die Matrix-ID wird nicht gefunden
Prüfen Sie: – Ist die Matrix-ID vollständig? – Beginnt sie mit @? – Ist der Servername nach dem Doppelpunkt korrekt? – Hat die externe Person Ihnen wirklich die Matrix-ID gegeben und nicht nur eine E-Mail-Adresse?
Einladung kommt nicht an
Mögliche Ursachen: – Der externe Server erlaubt keine Föderation. – Der eigene oder der externe Server blockiert die Verbindung. – Der externe Server ist vorübergehend nicht erreichbar. – Die Matrix-ID ist falsch geschrieben. – Der Raum erlaubt keine externen Mitglieder. – Sie haben nicht die nötigen Rechte, um Personen einzuladen. Lösung: Matrix-ID prüfen, Dokumentation oder Support kontaktieren.
Sie dürfen niemanden einladen
Dann fehlen Ihnen vermutlich die nötigen Rechte im Raum. Bitten Sie eine Person mit Administrations- oder Moderationsrechten, die Einladung vorzunehmen oder Ihre Rechte anzupassen.
Externe Person sieht alte Nachrichten nicht
Das kann an den Einstellungen zur Nachrichtenhistorie liegen. Je nach Einstellung sehen neue Mitglieder nur Nachrichten ab ihrem Beitritt. Lösung: Wichtige Informationen gezielt erneut teilen oder zusammenfassen.
Der externe Server blockiert die Föderation
Kontaktieren Sie den Support der externen Einrichtung oder nutzen Sie einen alternativen Kommunikationsweg (z. B. E-Mail).
7. Selbst an einem Raum auf einem anderen Matrix-Server teilnehmen
Nicht nur externe Personen können in Räume der Universität Wuppertal eingeladen werden. Auch Sie selbst können mit Ihrer Uni-Wuppertal-Matrix-ID an Räumen auf anderen Matrix-Servern teilnehmen – sofern die Föderation funktioniert und der fremde Raum dies erlaubt.
Ihre Matrix-ID hat diese Form: @benutzername:uni-wuppertal.de
Beispiel: @mmustermann:uni-wuppertal.de
Möglichkeit 1: Sie werden eingeladen
Der einfachste Weg ist eine Einladung durch eine Person, die bereits Mitglied im externen Raum ist.
Geben Sie dieser Person Ihre Matrix-ID (z. B. @mmustermann:uni-wuppertal.de).
Die externe Person lädt Sie dann mit dieser Matrix-ID in den Raum ein.
In Element erscheint anschließend eine Einladung, die Sie annehmen oder ablehnen können.
Möglichkeit 2: Sie treten über einen Raum-Link bei
Manche Räume können über einen Link geteilt werden.
Erhalten Sie einen Raum-Link (z. B. von einer externen Person).
Öffnen Sie den Link in Element.
Element fragt dann, ob Sie dem Raum beitreten möchten.
Ob der Beitritt möglich ist, hängt von den Einstellungen des externen Raums ab.
⚠️ Sicherheitstipp: Raum-Links können missbraucht werden, wenn sie öffentlich geteilt werden. Nutzen Sie Links nur von vertrauenswürdigen Quellen und prüfen Sie die Raumregeln, bevor Sie beitreten.
Möglichkeit 3: Sie treten über einen Raum-Alias bei
Ein Raum kann einen Alias haben, zum Beispiel: #projekt:matrix.org oder #projekt:uni-andere-stadt.de
In Element können Sie nach einem Raum suchen oder direkt den Alias eingeben.
Wenn der Raum öffentlich ist oder Beitrittsanfragen erlaubt, können Sie dem Raum beitreten oder eine Anfrage stellen.
8. Was ist beim Beitritt zu externen Räumen zu beachten?
8.1 Sie kommunizieren außerhalb des eigenen Servers
Wenn Sie einem Raum auf einem anderen Server beitreten, werden Raumdaten zwischen mehreren Matrix-Servern ausgetauscht.
Technisch notwendig, damit alle Beteiligten dieselben Nachrichten sehen können.
Der technische Matrix-Server der Universität Wuppertal heißt: matrixsrv.uni-wuppertal.de
Für andere Teilnehmende sichtbar ist in der Regel Ihre Matrix-ID (z. B. @benutzername:uni-wuppertal.de).
⚠️ Achtung: Teilen Sie keine Informationen in externen Räumen, die dort nicht hingehören.
8.2 Datenschutz und Vertraulichkeit beachten
Prüfen Sie vor dem Teilen von Informationen:
✅ Darf diese Information mit externen Personen geteilt werden?
✅ Handelt es sich um personenbezogene Daten?
✅ Handelt es sich um vertrauliche interne Informationen?
✅ Ist der externe Raum geeignet für diese Kommunikation?
💡 Empfehlung: Im Zweifel sollten Sie Rücksprache mit Ihrer Führungskraft, dem Datenschutz oder der zuständigen Stelle halten.
8.3 Raumregeln beachten
Externe Räume können eigene Regeln haben. Dazu gehören zum Beispiel:
wer schreiben darf,
ob Dateien hochgeladen werden dürfen,
welche Themen erlaubt sind,
ob Nachrichten moderiert werden.
💡 Empfehlung: Lesen Sie vorhandene Raumbeschreibungen oder angepinnte Nachrichten.
9. Gute Praxis für Räume mit externen Teilnehmenden
Für die Zusammenarbeit mit externen Personen empfiehlt sich ein bewusst eingerichteter Raum.
Empfehlungen
✅ Erstellen Sie für externe Zusammenarbeit lieber einen eigenen Raum. ✅ Benennen Sie den Raum eindeutig (z. B. mit Projekt- oder Arbeitsgruppennamen). ✅ Prüfen Sie, wer Personen einladen darf. ✅ Prüfen Sie die Sichtbarkeit der Nachrichtenhistorie. ✅ Laden Sie nur Personen ein, die wirklich teilnehmen sollen. ✅ Entfernen Sie Personen, wenn sie nicht mehr beteiligt sind. ✅ Teilen Sie keine vertraulichen Informationen, wenn der Raum dafür nicht vorgesehen ist. ✅ Verweisen Sie neue Mitglieder auf wichtige Regeln oder angepinnte Informationen. ✅ Prüfen Sie bei Problemen die Dokumentation der Universität Wuppertal: 🔗 siehe Dokumentation
10. Kurzanleitung: Externe Person in einen Uni-Wuppertal-Raum einladen
13. Wie erstelle ich einen Einladungslink für meinen eigenen Raum?
In Matrix können Sie Einladungslinks für Ihre Räume erstellen, um externen Personen den Beitritt zu erleichtern. Diese Links sind besonders nützlich, wenn die externe Person keine Matrix-ID hat oder Sie die ID nicht kennen.
Voraussetzungen
Sie müssen Mitglied des Raums sein.
Sie benötigen die passenden Rechte (meist Moderator oder Administrator).
Der Raum muss Einladungslinks erlauben (privat oder öffentlich mit Beitrittsoption).
Schritt-für-Schritt-Anleitung
Schritt 1: Raum öffnen
Öffnen Sie in Element den Raum, für den Sie einen Einladungslink erstellen möchten.
Schritt 2: Raumeinstellungen öffnen
Klicken Sie in der rechten Seitenleiste auf das Raum-Symbol (🏠) oder „Rauminfo“.
Hinweis: Die genaue Position und Bezeichnung kann je nach Element-Version oder App (Web, Desktop, Mobile) unterschiedlich sein.
Wählen Sie „Einstellungen“ oder „Raum verwalten“ aus.
Schritt 3: Einladungslink erstellen
Suchen Sie nach der Option „Link zum Raum“ oder „Einladungslink“.
Klicken Sie auf „Link generieren“ oder „Einladungslink erstellen“.
Wählen Sie aus, ob der Link:
Einmalig (nur für eine Person gültig) oder
Wiederverwendbar (für mehrere Personen) sein soll.
Legen Sie fest, ob der Link ablaufen soll (z. B. nach 24 Stunden oder einer Woche).
Bestätigen Sie die Erstellung.
Schritt 4: Link teilen
Der generierte Link sieht in der Regel so aus: https://matrix.to/#/#raumname:uni-wuppertal.de?via=uni-wuppertal.de
Kopieren Sie den Link und teilen Sie ihn mit der externen Person (z. B. per E-Mail oder Messenger).
Wichtige Hinweise zu Einladungslinks
✅ Vorteile:
Externe Personen können dem Raum ohne Matrix-ID beitreten (sie müssen sich nur auf ihrem Server registrieren).
Einfacher als das manuelle Einladen per Matrix-ID.
⚠️ Sicherheitshinweise:
Wiederverwendbare Links können missbraucht werden, wenn sie öffentlich geteilt werden. → Nutzen Sie sie nur für vertrauenswürdige Personen oder begrenzte Zeiträume.
Privaträume: Selbst mit einem Link können externe Personen nur beitreten, wenn der Raum Föderation erlaubt und ihre Server verbunden sind.
Öffentliche Räume: Hier können Einladungslinks ohne Einschränkungen geteilt werden (Achtung: Datenschutz!).
Fazit
Matrix ermöglicht die Zusammenarbeit über Organisationsgrenzen hinweg.
Externe Personen können in Räume der Universität Wuppertal eingeladen werden, wenn:
ihre Matrix-ID bekannt ist (z. B. @name:matrix.org oder @name:uni-andere-stadt.de),
die Raumrechte passen,
die beteiligten Server miteinander kommunizieren dürfen (Föderation).
Die Matrix-ID von Mitarbeitenden der Universität Wuppertal hat diese Form: @benutzername:uni-wuppertal.de
Der technische Matrix-Server der Universität Wuppertal heißt: matrixsrv.uni-wuppertal.de
Umgekehrt können Mitarbeitende der Universität Wuppertal auch an Räumen auf anderen Matrix-Servern teilnehmen – entweder per:
Einladung,
Raum-Link,
Raum-Alias.
⚠️ Wichtig: Vor der Zusammenarbeit mit externen Personen sollten Raumrechte, Sichtbarkeit der Nachrichtenhistorie, Verschlüsselung und Datenschutz bewusst geprüft werden.
Für konkrete Angaben zur Anmeldung, Nutzung und aktuellen Regelungen sollte immer die offizielle Dokumentation der Universität Wuppertal genutzt werden: 🔗 https://element.uni-wuppertal.de/docs/
Das Vorgehen unterscheidet sich bei den beiden vorhandenen Instanzen für studentische Umfragen und für Umfragen von Mitarbeitenden:
Umfragen von Mitarbeitenden:
Damit wir Ihnen bzw. den Umfrage-Teilnehmenden möglichst lange gleich aussehende Umfragen bereitstellen können, um bei länger laufenden Studien mögliche Effekte der Beeinflussung durch das Layout zu minimieren, erfolgt die Umstellung in mehreren Schritten mit einer Übergangsadresse:
31.08.2026: Die Instanz umfrage.uni-wuppertal.de und alle Umfragen werden auf die Übergangsdomain umfrage2.uni-wuppertal.de kopiert. Die Umfragen bleiben unter der bekannten URL im bisherigen Layout noch bis zum 30.11.2026 erreichbar. umfrage2.uni-wuppertal.de erhält – ähnlich wie bisher – ein Layout angelehnt an den Stil der BUW-Website.
01.12.2026: Abschaltung der Domain umfrage.uni-wuppertal.de – bis zum 01.02.2027
01.02.2027: Alle Umfragen von umfrage2 werden auf umfrage.uni-wuppertal.de übertragen. Weiterleitung von umfrage2.uni-wuppertal.de auf umfrage.uni-wuppertal.de wird eingerichtet.
30.03.2027: Abschaltung der Übergangsdomain umfrage2.uni-wuppertal.de
Übersicht der Verfügbarkeit der Instanzen in den nächsten 12 Monaten
Was bedeutet das für Ihre Umfragen?
Ab 31.08.2026: Legen Sie keine Umfragen mehr auf umfrage.uni-wuppertal.de, sondern stattdessen auf der Übergangsdomain umfrage2.uni-wuppertal.de an. Ihre bestehenden Umfragen werden dort schon sein.
Umfragen, die nach dem 31.08.2026 auf umfrage2.uni-wuppertal.de angelegt werden, sind im neuen Layout und nach dem 01.02.2027 auch unter umfrage.uni-wuppertal.de aufrufbar.
Am 01.02.2027: Legen Sie Ihre Umfragen wieder regulär auf umfrage.uni-wuppertal.de an.
Achtung:
Umfragen, die nach dem 30.08.2026 auf umfrage.uni-wuppertal.de angelegt werden, werden nach dem 30.11.2026 nicht mehr erreichbar sein.
Umfragen, die vor dem 31.08.2026 auf umfrage.uni-wuppertal.de angelegt wurden, werden ab dem 01.02.2027 im neuen Design auftauchen – allerdings ohne die Antworten, die zwischen dem 31.08.2026 und 30.11.2026 eingegangen sein sollten. Diese Antworten haben Sie um den 30.11.2026 gesichert.
Studentische Umfragen:
31.08.2026: Migration der Instanz studentische-umfrage.uni-wuppertal.de von Version 6 auf Version 7. Verwendung eines leicht abgewandelten neuen Standard-Layouts. Bestehende Umfragen laufen unter der gleichen URL sofort im neuen Layout weiter. Neue Umfragen können einfach angelegt werden.
Allgemein gilt:
Bitte beachten Sie bei der Erstellung von Umfragen weiterhin die Inhalte folgender Websites:
Umfragen, bei denen personenbezogene Daten erhoben werden, sind ein großer Quell der Erkenntnis. Deswegen sind die Ergebnisse auch begehrt in der Welt da draußen.
Die LimeSurvey-Instanzen, die vom ZIM für alle Mitglieder der Bergischen Universität Wuppertal bereitgestellt werden, werden unter der Prämisse der Datensparsamkeit gepflegt.
Datensparsamkeit heißt zum einen, dass nicht alle Accounts der BUW auf das Drittsystem ausgerollt werden, zum anderen, dass die Daten nach Abschluss der Umfrage nicht unbegrenzt auf der Plattform vorgehalten werden.
Ersteres bedingt, dass sich jeder Account mindestens 1x angemeldet haben muss – auf der Instanz, die dem jeweiligen Personenkreis zur Verfügung gestellt wird –, bevor er zur gemeinsamen Bearbeitung einer Umfrage hinzugefügt werden kann.
Das nicht unbegrenzte Vorhalten der Daten nach Abschluss der Umfragen ist von den Umfrageerstellenden in den Dokumentationen zur Verarbeitungstätigkeit einzutragen:
Antwort- und eventuelle Token-Tabellen deaktivierter oder abgelaufener Umfragen werden durch das ZIM im halbjährlichen Turnus gelöscht, also 6 Monate nach Erhebungsende. Die Umfrage selbst, wenn sie deaktiviert oder abgelaufen ist, wird nach 24 Monaten gelöscht.
Daher bitte nach Beendigung von Umfragen alle Ergebnisse und Umfragen vom Server exportieren und am besten selbst löschen.