Für die meisten Nutzer*innen ist die Wahl des richtigen KI‑Modells in vielen Chatoberflächen ein Blindflug: Man klickt auf „Standard“, „schnell“ oder „präzise“ – was dahinter steckt, bleibt oft unklar.
genAI4BUW verfügt über ein Feature um Infos anzuzeigen, die sonst verborgen bleiben: eine detaillierte Modellübersicht. Hier lassen sich Fähigkeiten, Grenzen und Betriebsbedingungen der Modelle auf einen Blick vergleichen.
Die Startseite für alle Modelle
Im Zentrum steht der Titel „Modellübersicht“, darunter drei Reiter:
- Text
- Bild
- Embedding
Im obigen Screenshot ist der Tab „Text“ aktiv – hier finden sich alle textbasierten Chatmodelle. Der Aufbau ist immer gleich: Die Bild- und Embedding‑Modelle werden nach demselben Schema dargestellt.
Rechts oben sitzt ein Button „Glossar“ – ein dezenter, aber wichtiger Hinweis: Wer Begriffe wie „Temperature“, „TopP“ oder „Presence Penalty“ nicht aus dem Effeff kennt, kann sie direkt in der Oberfläche nachschlagen.
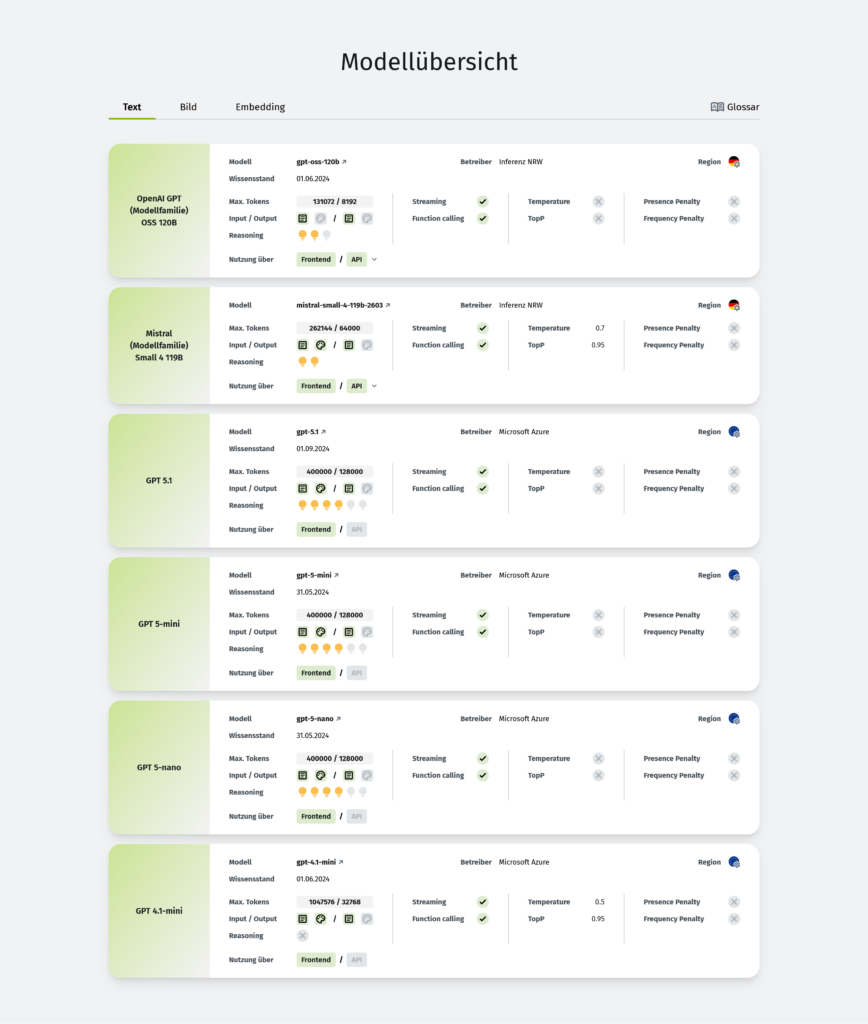
Karten statt Dropdown: Wie die Modelle dargestellt werden
Jedes Modell wird als eigene Karte dargestellt, mit einem farbigen Streifen links, der die Modellfamilie markiert. Dies sind derzeit (Stand April 2026):
- OpenAI GPT (OSS 12B)
- Mistral (Small 4 119B)
- GPT 5.1
- GPT 5‑mini
- GPT 5‑nano
- GPT 4.1‑mini
Dieser Aufbau vermeidet kryptische Kürzel in einem Dropdown-Menü. Stattdessen erkennt man sofort:
- zu welcher Familie ein Modell gehört,
- ob es sich um ein Open‑Weight‑Modell (z.B. über „Inference NRW“) oder ein kommerzielles Cloud‑Modell (z.B. über Microsoft Azure) handelt,
- und in welcher Region es betrieben wird – symbolisiert durch Flaggen bzw. Region-Icons.
Gerade für Einrichtungen, die Wert darauf legen müssen, wo und wie ihre Daten verarbeitet werden sind diese Informationen hilfreich.
Was pro Modell sichtbar ist
Die Karten sind standardisiert. Pro Modell sind u.a. folgende Details zu sehen:
1. Metadaten des Modells
- Konkreter Modellname
Etwagpt-oss-12b-2odergpt-5.1. - Wissensstand / Stand des Trainings
Beispielsweise „01.06.2024“. Damit ist klar: Auf welchen Zeitraum spielt das Modell sein Weltwissen zurück? - Betreiber
Etwa Inference NRW oder Microsoft Azure. Für technische Nutzer ist das entscheidend, um Infrastruktur, Latenz und Datenschutz einzuordnen. - Region
Über Flaggen bzw. Symbole visualisiert. So lässt sich erkennen, ob Anfragen im EU‑Kontext verarbeitet werden oder nicht. - Wenn ein API Zugriff verfügbar ist:
Der API Model Name und der zu verwendende Endpunkt, diesen verwenden Entwickler um das Modell in der Programmierung gezielt anzusprechen. Zum Beispielinferenz-gpt-oss-120bsowiev1/chat/completions
2. Tokenlimits und I/O‑Kapazität
Prominent platziert ist die Maximalanzahl an Tokens:
- Input / Output, z.B.
400000 / 128000Tokens.
In einer Zeit, in der Kontexte mit mehreren hundert Seiten keine Seltenheit mehr sind, ist das kein „Nice to have“, sondern Planungsgrundlage: Wer große Dokumente oder lange Chatverläufe einspeisen will, braucht genau diese Zahlen.
3. Fähigkeiten und Features
Unter „Reasoning“ bzw. in Form von Symbolen werden modellbezogene Fähigkeiten gekennzeichnet, z.B.:
- erweiterte Reasoning‑Fähigkeiten (z.B. für komplexe Analyseaufgaben),
- Unterstützung für Tool‑/Function Calling,
- Streaming‑Unterstützung (Antwort kommt tokenweise).
Ob ein Feature unterstützt wird, ist jeweils klar durch ein Häkchen bzw. ein ausgegrautes Symbol erkennbar. So lässt sich etwa ein „voll ausgestattetes“ GPT‑5.1‑Modell schnell von einer leichteren Mini‑Variante unterscheiden.
4. Steuerparameter für die Ausgabe
Spannend ist, dass klassische Sampling‑Parameter direkt aufgelistet sind:
- Temperature
- TopP
- Presence Penalty
- Frequency Penalty
5. Zugangswege: Frontend vs. API
Am unteren Rand jeder Karte steht:
- „Nutzung über: Frontend | API“
Damit ist sofort klar, ob ein Modell nur im Chat-Frontend zur Verfügung steht oder auch über eine Programmierschnittstelle. Für Entwickler bedeutet das: Die UI ist nicht Endpunkt, sondern Schaufenster für die zugrundeliegende Plattform.
Vergleich statt Rätselraten
Der eigentliche Mehrwert der Übersicht liegt in der direkten Vergleichbarkeit:
- Wer viel Kontext braucht, sieht, dass z.B. GPT‑5.1 und GPT‑5‑mini ähnliche Tokenlimits bieten, während andere Modelle stärker begrenzt sein könnten.
- Wer besonderen Wert auf On‑Prem‑ oder EU‑nahe Verarbeitung legt, erkennt die Modelle, die über „Inference NRW“ mit Länderflagge laufen – im Gegensatz zu Cloud‑Varianten via Azure.
- Wer nur einfache, schnelle Antworten benötigt, kann gezielt zu „Mini“‑ oder „Nano“‑Modellen greifen, statt unnötig große und teure Modelle einzusetzen.
Fazit
Die hier gezeigte Modellübersicht holt etwas an die Oberfläche, das in vielen KI‑Chats im Verborgenen bleibt: die innere Vielfalt der Modelle, auf denen der Assistent tatsächlich läuft. Statt „eine KI“ gibt es hier eine klar kuratierte Palette von Modellen, jedes mit eigenem Profil, klaren Grenzen und dokumentierten Fähigkeiten.