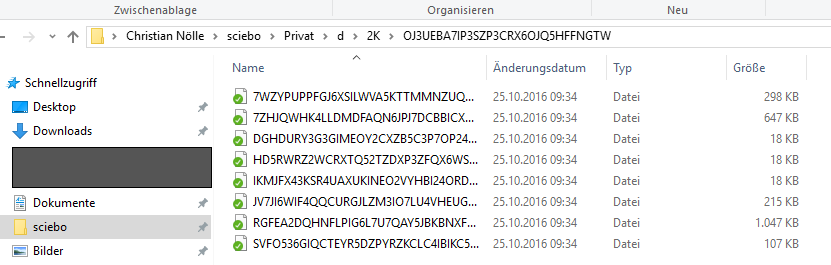
Kennen wir alle: Wir legen privaten Daten (Bilder, Dokumente etc.) in die Cloud. Laden das bei Dropbox hoch, oder besser, nutzen den Dienst Sciebo. Nun liegen die Daten dort zwar relativ sicher, trotzdem kann theoretisch jeder die Daten einsehen. Sei es der Sciebo-Admin, ein unberechtigter Dritter, der mein Passwort gehackt hat, oder oder oder. Aus diesem Grund dürfen dienstliche Daten mit hohem oder sehr hohem Schutzbedarf dort gar nicht abgelegt werden – bitte hier die Handlungsempfehlung zu Sciebo beachten.
Nun ist Ihr Umgang mit privaten Daten natürlich grundsätzlich Ihnen überlassen. Ich speichere beispielsweise Fotos, die ich mit meinem Smartphone mache, auf Sciebo. Um ein zentrales “Backup” zu haben, damit ich sie nicht Google geben muss und um die Bilder auf verschiedenen Geräten synchron und damit zugreifbar zu halten. Aber ich möchte nicht, dass diese dort im Klartext liegen. Lange Rede, kurzer Sinn: Verschlüsselung muss her! Und da gibt es nun seit einiger Zeit das wirklich gute Tool Cryptomator.
Die Software ist Open Source, wird aktiv weiterentwickelt und ist einfach zu handhaben.
Um unter Windows einen neuen Tresor anzulegen, erstellen Sie einfach einen neuen Ordner in Sciebo, wählen diesen in Cryptomator aus, legen ein sicheres (!) Passwort fest (niemals vergessen, Sie können das nicht wiederherstellen – Ihre Daten wären verloren) und schon bindet die Software Ihnen ein neues Netzlaufwerk ein.
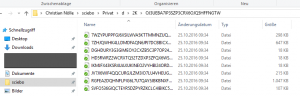 Auf diesem können Sie nun all ihre sensiblen Daten abspeichern, die Verschlüsselung übernimmt Cryptomator transparent im Hintergrund vor. Innerhalb Ihrers Cloud-Speichers können Sie nun sehen, wie in dem als “Tresor” gekennzeichneten Ordner Ihre Dateien, bzw. deren verschlüsselte Varianten, abgelegt werden. Rückschlüsse auf Dateinamen oder Ordnerstrukturen sind nicht möglich.
Auf diesem können Sie nun all ihre sensiblen Daten abspeichern, die Verschlüsselung übernimmt Cryptomator transparent im Hintergrund vor. Innerhalb Ihrers Cloud-Speichers können Sie nun sehen, wie in dem als “Tresor” gekennzeichneten Ordner Ihre Dateien, bzw. deren verschlüsselte Varianten, abgelegt werden. Rückschlüsse auf Dateinamen oder Ordnerstrukturen sind nicht möglich.
Es existieren Varianten für alle gängigen Betriebssysteme, lediglich für Android ist erst eine frühe Betaversion erschienen. Hier wird aber der Funktionsumfang auch in den nächsten Monaten den Versionen für Windows, OS X oder iOS angeglichen werden.